Dave Tweed — May 19, 2011
Feel free to send comments to “webmaster” at this site.
To do: Discuss backup, security issues.
This document is not about the design of websites. Instead, it is about the hardware and software infrastructure that goes into building and maintaining websites.
For the purposes of this discussion, we’ll divide websites into two broad classes: static and dynamic. On a static website, the HTTP server (e.g., Apache) simply handles requests for files from the web browser and delivers them. On a dynamic website, the HTTP server also interacts with custom software to generate content, in addition to serving files. The custom software can be anything from CGI scripts to a full-blown content-management system (CMS) such as Drupal or Joomla.
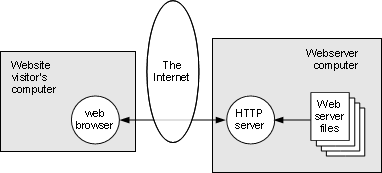
Figure 2-1: Visiting a static website |
When a visitor interacts with a static website, as shown in Figure 2-1, the visitor’s web browser on the left makes requests of the HTTP server (software) running on the web server (hardware), and the server delivers the contents of the files in response. The files generally consist of web pages (in HTML), style sheets (in CSS) and client-side scripts (in JavaScript), in addition to supporting files such as images (photographs and drawings) and sounds.
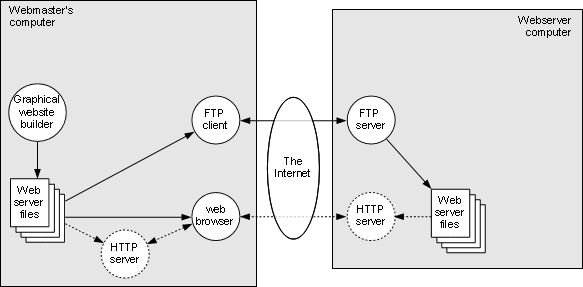
Figure 2-2: Constructing a static website with basic tools |
So, the key question is, how do those files get on the server? That’s the responsibility of the webmaster.
In the simplest possible scenario, shown in Figure 2-2, the webmaster is also the content developer. The webmaster constructs the files for the website on his own machine, usually using some sort of interactive web builder software, but in some cases by editing the files directly with a text editor (in conjunction with appropriate tools to prepare image and sound files). He can test the website locally, usually by simply pointing his browser at the files, but in some cases, it may be necessary to run a local web server as well.
When the website looks correct, the files are copied verbatim to the web server, using some sort of file transfer utility, usually some variant of FTP, but rsync (tunneled through ssh for security) is another popular choice. Many interactive web building tools include an FTP client internally to support “publishing” the website to the server.
Note that it isn’t absolutely necessary to test the website locally before transferring it to the server; it can be tested “live” via the regular browser interaction with the web server.
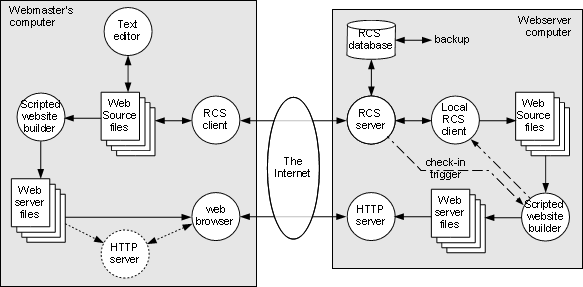
Figure 2-3: Shared development of a static website |
As a website becomes larger and more complex, it can be necessary for more than one person to be working on different aspects of it. One approach to dealing with this is shown in Figure 2-3, which introduces a couple of new concepts.
The first problem is that interactive, GUI-based website building tools generally do not extend well to multi-person development. Therefore, we introduce the concept of a scripted website building technique, in which command-line tools such as Perl scripts are executed under control of a master program such as “make”. These scripts produce the actual files needed by the web server, often by applying styling and navigation templates to files that contain the website content.
This allows, for example, the webmaster to concentrate on the scripts and templates themselves, while other developers concentrate on specific areas of content (text, images, etc.). When something changes, the webmaster just needs to invoke “make” to create a fresh set of files for the web server. All of the detailed knowledge required to do this has been captured in the corresponding “Makefile”.
The second problem is that multiple developers can get in each other’s way, for example, by trying to make different modifications to the same source file. This problem is easily addressed by using a revision control system (RCS) such as CVS or Subversion. Furthermore, it very likely that the various developers won’t be located near each other (e.g., in the same building), so it makes sense to put the RCS server and its database on the webserver computer, where everyone involved can access it.
Each developer runs an RCS client program that allows them to “check out” files that need to be modified, creating local copies on the developer’s computer for editing. Once the changes have been made, the RCS “check in” process helps to manage any conflicts with other developers. Depending on the type of work the developer is doing, he may or may not do local testing of his changes before checking them into the RCS. If he does, then he’ll need a local copy of the website builder scripts and the tools to run them (e.g., make and Perl).
Furthermore, the check-in operation on the RCS server can trigger a copy of the website builder script on the website server computer to automatically rebuild the website files with the changes. The website builder process interacts with a local copy of the RCS client to get the latest versions of the web source files from the RCS database.
Many interesting and interactive features can be added to a website through the use of client-side scripting. All of the major browsers now include a built-in interpreter for a language called “JavaScript” (a.k.a. “ECMAscript”), and this allows the browser to react to actions by the user without having to interact with the web server, making the whole experience much more engaging. Other languages (e.g., Java) and features can be added to browsers through the use of “plug-ins” and “add-ons”.
However, from the web server’s point of view, the website is still a static one, in the sense that nothing on the server changes as a result of the user’s actions. For now, I’m not going to say anything further about client-side scripting, becuase it doesn’t fundamentally change how the underlying website development infrastructure works.
Just like web browsers, most HTTP servers can also have their functionality extended through the use of scripts, and this is called server-side scripting. It is this capability that gives the website visitor the basic ability to change the state of the web server itself, allowing features such as user accounts and all of the persistent features associated with them, such as blogs, wikis, forums, etc. This is the point at which you start to have what we’re calling a dynamic website.
The original, and most basic way of doing this is known as the Common Gateway Interface (CGI), and it simply allows the server to invoke an external program and pass information from the current HTTP request to that program. The first such programs were Perl scripts, since that was an early and popular scripting language available on servers, but in fact, any scripted or compiled language available on the webserver computer can be used.
Nowadays, it is much more common to invoke server-side scripts by means of file extensions that the HTTP server is set up to recognize. For example, if a request comes in for a file called “index.php”, the HTTP server will automatically feed the file to a PHP interpreter and then send the output of the interpreter to the web browser.
Note that not all server-side scripting is used to create a dynamic website. Sometimes, server-side scripting is just used to transform web pages in a fixed way, such as applying styling or navigation templates. This is not really any different from the scripted building of static websites discussed in Section 2.2; the only difference is that the templates get applied every time the page is requested by a website visitor, rather than just once when the page is updated by the developer.
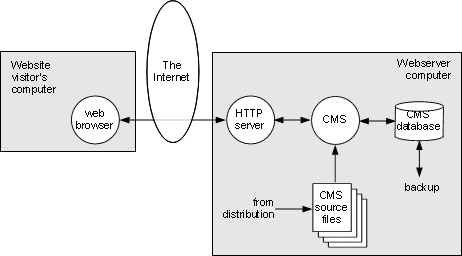
Figure 5-1: Visiting a dynamic website |
Server-side scripts have now evolved to the point where we now have what are called content-management systems (CMSs), which are large collections of scripts that interact with a database in which the website content is stored. Two popular examples are Drupal and Joomla. The CMS manages the creation and use of user accounts and both the entering and displaying (through styling and navigation templates) of website content. Most CMSs are themselves extendable through the use of 3rd-party modules and templates, which can provide features such as blogs, wikis, forums, photo galleries and more within the structure of the website.
From an infrastructure point of view, visiting a CMS-based website is not hugely different from visiting a static website, as shown in Figure 5-1. The webmaster has set up the CMS from its distribution archive, which includes both the scripts and a standard set of templates and modules. He has also set up the database that the CMS will use to store website content.
At this point, both the webmaster and any other developers for the website interact with the CMS through their regular web browsers to create user accounts and content for the website.
Note that not every visitor to this type of website needs to have a user account. There will always be some part of the website content available to “anonymous” visitors, and this is under the control of the developers.
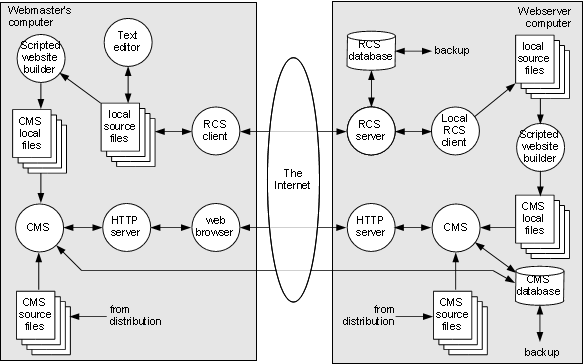
Figure 5-2: Development of a dynamic website |
However, the picture in Figure 5-1 is overly simplistic. It is rare for a website to use only the modules and templates that come with the distribution; in general, the webmaster is going to customize the website with newly-developed and/or 3rd-party templates and modules, and this needs to be managed appropriately. For this reason, we introduce the infrastructure shown in Figure 5-2.
Just like with the static website, an RCS is used to hold site-specific code and data. And like before, a scripting system is used to build the CMS files from higher-level source files — not so much for 3rd-party options, but this could be useful for locally-developed features.
Note that if the webmaster (or any other developer working at this level) is going to test the website on his own machine, he’s going to have to replicate essentially the entire setup of the web server, including copies of the build scripts, the CMS itself and an HTTP server. The local copy of the CMS will be able to interact with the master CMS database as shown here, but it might be better to use a replicated copy to prevent design errors from affecting the live website. Developers working only on content do not need to worry about this; they continue to use only their web browsers, as shown in Figure 5-1.
— End of Document —